
Defining the architecture requirements
We have defined the characteristics of our system so we know how we want it to behave. In order to obtain that behavior though, we need to determine what architectural features will get us there. Let’s go through our business requirements one by one and come up with some technical requirements to guide us through the project.
Easy to develop
We need a way to make changes to the system in order to move it forward that is easy to work with and as simple as possible. Developing in production may seem easy at first, but over time this creates a lack of trust in the system as well as a lot of downtime. Instead, let’s implement these technical features to make changing this system sustainable:
- New developers can get going by cloning the repo and running a command
- Everything can be run locally for development purposes
- Resetting to a known good state is quick and easy
Getting started workflow
PWD: ~/code
# Ok, let's get you setup FNG
git clone git@github.com:technolo-g/modern-jenkins.git
cd modern-jenkins/deploy/master/
./start.sh
# You should be all set! You can begin development now.Safe to develop
The nature of a CI system is to verify code exhibits the qualities we want and expect it to then deliver it production. This makes it inherently dangerous as it is extremely powerful and programmed to deliver software to production. We need the ability to modify this system without interfering with production by accident. To accomplish this we will implement:
- Splitting development and production credentials
- Disabling potentially dangerous actions in development
- Explicitly working with forks when possible
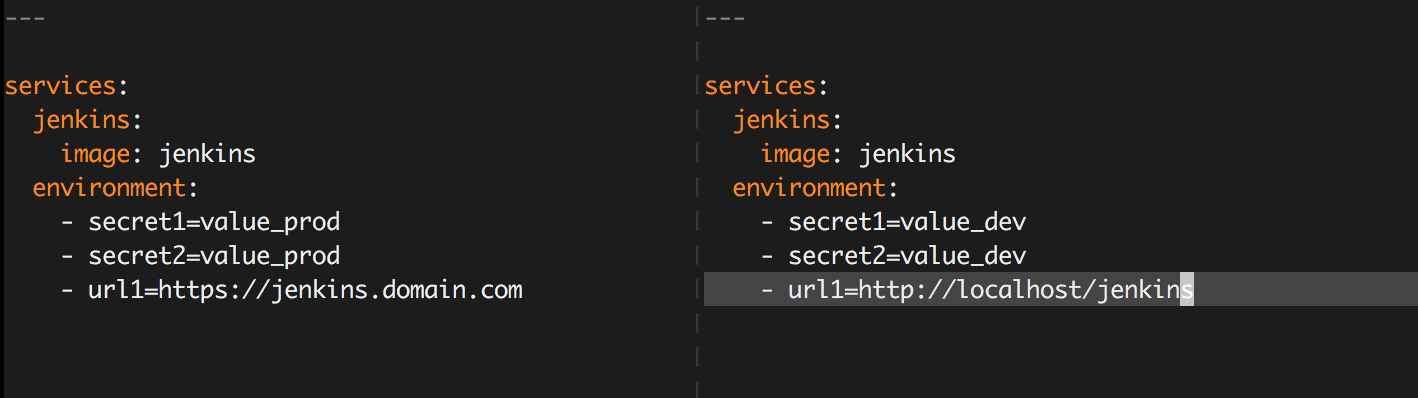
Consistently deployable
This system, when deployed to production, will be used by a large portion of your development team. What this means is that downtime in the build system == highly paid engineers playing chair hockey. We want our system to always be deployable in case there is an issue with the running instance and also to be able to quickly roll back if there is an issue with a new version or the like. To make this happen we will need:

- A versioning system that keeps track of the last known good deployment
- State persistence across deploys
- A roll-forward process
- A roll-back process
Easy to upgrade
The nature of software development involves large amounts of rapid change. Within our system this mostly consists of plugin updates, Jenkins war updates, and system level package updates. The smaller the change during an upgrade, the easier it is to pinpoint and fix any problems that occur and the way to do that is frequent upgrades. To make this a no-brainer we will:
- Build a new image on every change, pulling in new updates each time
- Automatically resolve plugin dependencies
- Smoke test upgrades before deployment

Programmatically configurable
Hand configuring complex systems never leads to the same system twice. There are lots of intricacies of the config including: order of operations, getting the proper values, dealing with secrets, and wiring up many independent systems. Keeping track of all this in a spreadsheet that we then manually enter into the running instance will get it done, but becomes pure nightmare mode after the first person is done working on it. Luckily with Jenkins’ built in Groovy init system 1, we will be able to configure Jenkins with code in a much more deterministic way. Most of this functionality is built in, but we will still need:

- A process to develop, test, and deploy our Groovy configuration
- A mechanism to deploy it along with the master
- The ability to share these scripts across environments
Immutable
With a consistently deployable, programmatically configured system it is almost as easy to redeploy instead of modifying the running instance. It is indeed easier to just click a checkbox in the GUI to change a setting the first time you do it, but the second, third, and fourth times become increasingly more difficult to remember to go check that box. For this reason, we are NEVER* going to mutate our running instance. We will instead just deploy a new version of our instance. This will only be a process change as the architectural features listed above will enable this process. We should however, document this process so that it will be followed by all.
- Documentation of how to get changes into production
100% in SCM
Everything we’re doing is ‘as code’ so we will store it in the source repository ‘as code’. This will include master configuration, secrets, job configuration, infrastructure provisioning and configuration, as well as anything else the system needs to operate. To support this we’ll need:
- A SCM repo (we’re using a Git repo hosted by GitHub)
- A layout that supports: - Docker containers - Deployment tooling - Job DSL - Secrets
- A mechanism for encrypting secrets in the repo
Git Repo Diagram
.
├── README.md
├── ansible
│ ├── playbook.yml
│ └── roles
├── deploy
│ ├── master
│ │ └── docker-compose.yml
│ └── slaves
├── images
│ ├── image1
│ │ └── Dockerfile
│ └── image2
│ └── Dockerfile
└── secure
├── secret1
└── secret2Secure
This pipeline can be considered the production line at a factory. It is where the individual components of your application are built, tested, assembled, packaged, and deployed to your customers. Any system that does the above mentioned processes should be heavily locked down as it is integral to the functioning of the company. Specifically we should:

- Keep secrets secure and unexposed
- Segregate actions by user (both machine and local)
- Create an audit trail for any changes to the production system
- Implement least-privilege access where necessary
- Apply patches as soon as is feasible
Scalable
If scalability is thought of from day 0 on a project it is much easier to implement than if it is bolted on later. These systems have a tend to grow over time and this growth should be able to happen freely. This is not always an easy task, but we will attempt to make it easier by:
- Keeping individual components de-coupled for independent scaling
- Not locking ourselves into a single platform or provider
- Monitoring the system to point out bottlenecks
Scaling to infinity… and beyond!

Now let’s start making some stuff!
Next Post: Code Repository and Development Lifecycle for a Jenkins + Docker CI/CD System