
A Docker Swarm SOA
One of the most exciting things that Docker Swarm brings to the table is the ability to create modern, resilient, and flexible architectures with very little overhead. Being able to interact with a heterogenious cluster of Docker hosts as if it were a single host enables the existing toolchains in use today to build everything we need to create a beautifully simple SOA!
This article is going to attempt to describe a full SOA architecture built around Docker Swarm that has the following properties:
- A hypervisor layer composed of individual Docker hosts (Docker/Registrator)
- A cluster layer tying the Docker hosts together (Docker Swarm)
- A service discovery layer (Consul)
- A routing layer to direct traffic based off of the services in Consul (HAProxy / Nginx)
Hypervisor Layer
The hypervisor layer is made up of a group of discrete Docker hosts. Each host has the services running on it that allows it to participate in the cluster:
-
Docker daemon: The Docker daemon is configured to listen on the network port in addition to the local Linux socket so that the Swarm daemon can communicate with it. In addition, each Dockerhost is configured to run with a set of tags that work with Swarm’s scheduler to define where containers are placed. They help describe the Docker host and is where any identifying information can be associated with the Docker host. This is an example of a set of tags a Docker host would be started with:
- zone: application/database
- disk: ssd/hdd
- env: dev/prod
-
Swarm daemon: The Swarm client daemon is run alongside the Docker daemon in order to keep the node in the Swarm cluster. This Swarm daemon is running in
joinmode and basically heartbeats to Consul to keep its record updated in the/swarmlocation. This record is what the Swarm master uses to create the cluster. If the daemon were to die the list in Consul should be updated to automatically to remove the node. The Swarm client daemon would use a path in Consul like/swarmand it would contain a list of the docker hosts: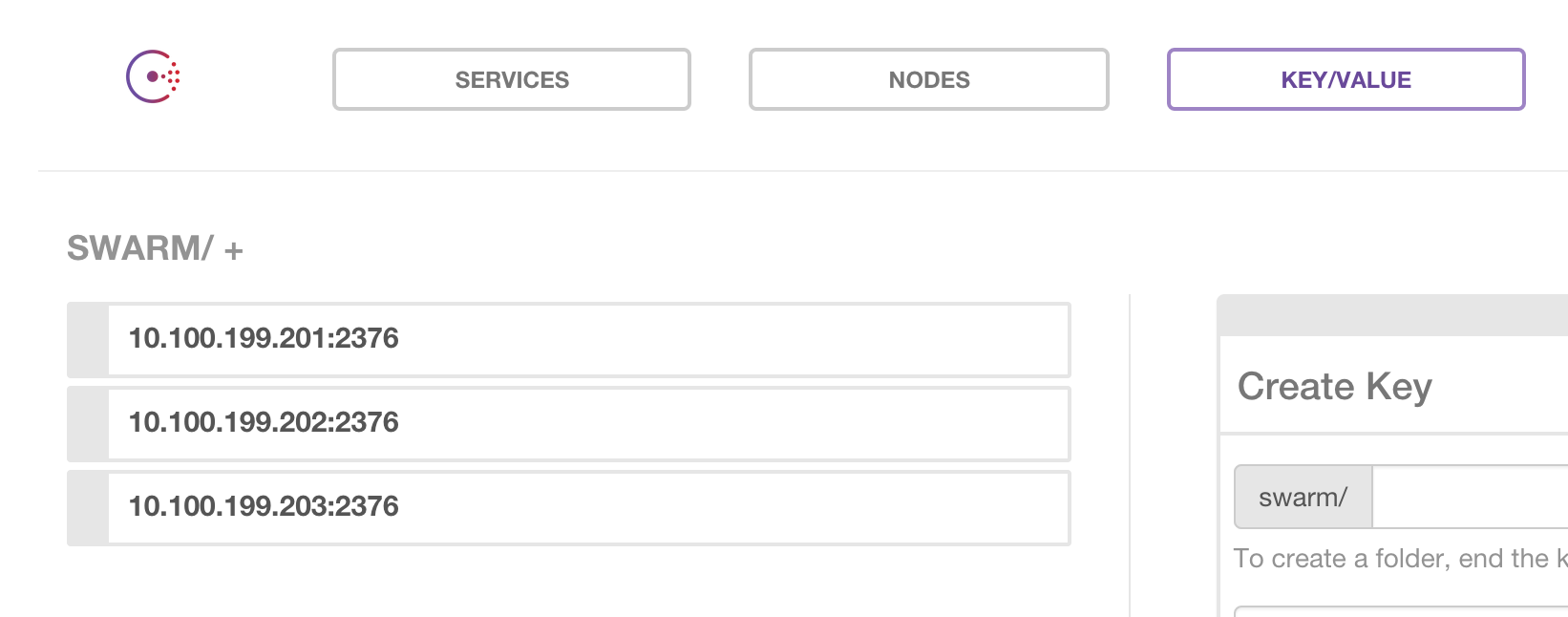
-
Registrator daemon: The Registrator app1 is what will be updating Consul when a container is created or destroyed. It listens to the Docker socket and upon each event will update the Consul key/value store. For example, an app named deepthought that requires 3 instances on separate hosts and that is running on port 80 would create a structure in Consul like this:
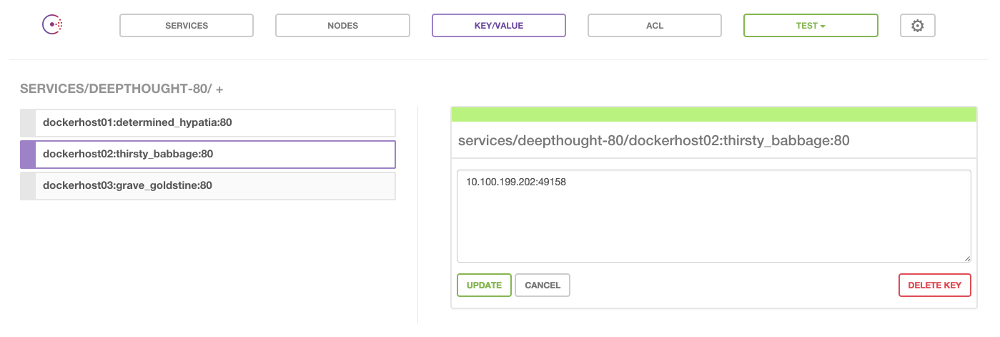
The pattern being:
/services/<service>-<port>/<dhost>:<cname>:<cport>value:<ipaddress>:<cport>- service: The name of the container’s image
- port: The container’s exposed port
- dhost: The Docker host that the container is running on
- cport: The Container’s exposed port
- ipaddress: The ipaddress of the Docker host running the container
The output of a
docker psfor the above service looks like so:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
097e142c1263 mbajor/deepthought:latest "nginx -g 'daemon of 17 seconds ago Up 13 seconds 10.100.199.203:49166->80/tcp dockerhost03/grave_goldstine
1f7f3bb944cc mbajor/deepthought:latest "nginx -g 'daemon of 18 seconds ago Up 14 seconds 10.100.199.201:49164->80/tcp dockerhost01/determined_hypatia
127641ff7d37 mbajor/deepthought:latest "nginx -g 'daemon of 20 seconds ago Up 16 seconds 10.100.199.202:49158->80/tcp dockerhost02/thirsty_babbage
This is the most basic way to record the services and locations. Registrator also supports passing metadata along with the container that includes key information about the service2.
Another thing to mention is that it seems the author of Registrator intends the daemon to be run as a Docker container. Since a Docker Swarm cluster is meant to be treated as a single Docker host, I prefer the idea of running the Registrator app as a daemon on the Docker hosts themselves. This allows a state on the cluster in which 0 containers are running and the cluster is still alive. It seems like a very appropriate place to draw the line between platform and applications.
Cluster Layer
At this layer we have the Docker Swarm master running. It is configured to read
from Consul’s key/value store under the /swarm prefix and it generates its
list of nodes from that information. It also is what listens for client connections
to Docker (create, delete, etc..) and routes those requests to the proper backend
Docker host. This means that it has the following requirements:
- Listening on the network
- Able to communicate with Consul
- Able to communicate with all of the Docker daemons
As of yet I have yet to see mention of making the Swarm daemon itself HA, but after working with it there really do not seem to be any reasons that it could not be. I expect that a load balancing proxy with TCP support (HAproxy) could be put in front of a few Swarm daemons with relative ease. Sticky sessions would have to be enabled and possibly an active/passive if there are state synchronization issues between multiple Swarm daemons, but it seems like it would be doable. Since the containers do continue to run and are accessible even in the case of a Swarm failure we are going to accept the risk of a non-ha Swarm node over the complexity and overhead of loadbalancing the nodes. Tradeoffs right?
Service Discovery Layer
The service discovery layer is run on a cluster of Consul nodes; specifically it’s key/value store. In order to maintain quorum (n/2 + 1 nodes) even in the case of a failure there should be an odd number of nodes. Consul has a very large feature set3 including auto service discovery, health checking, and a key/value store to name a few. We are only using the key/value store, but I would expect there are benefits to incorporating the other aspects of Consul into your architecture. For this example configuration, the following processes are acting on the key/value store:
- The Swarm clients on the Docker hosts will be registering themselves in
/swarm - The Swarm master will be reading
/swarmin order to build its list of Docker hosts - The Registrator daemon will be taking nodes in and out of the
/servicesprefix - Consul-template will be reading the key/value store to generate the configs for the routing layer
This is the central datastore for all of the clustering metadata. Consul is what ties the containers on the Docker hosts to the entries in the routing backend.
Consul also has a GUI that can be installed in addition to everything else and I highly recommend installing it for development work. It makes figuring out what has been registered and where much easier. Once the cluster is up and running you may have no more need for it though
Routing Layer
This is the edge layer and what all external application traffic will run through. These nodes are on the edge of the Swarm cluster and are statically IP’d and have DNS entries that can be CNAME’d to for any services run on the cluster. These nodes listen on port 80/443 etc.. and have the following services running:
-
Consul-template: This daemon is polling Consul’s key/value store (under
/servicesand when it detects a change, it writes a new HAProxy/Nginx config and gracefully reloads the service. The templates are written in Go templating and the output should be in standard HAProxy or Nginx form. -
HAProxy or Nginx: Either of these servers are fully battle proven and ready for anything that is needed, even on the edge. The service is configured dynamically by Consul-template and reloaded when needed. The main change that happens frequently is the modification of a list of backends for a particular vhost. Since the list is maintained by what is actually alive and in Consul it changes as frequently as the containers do.
This is a high level overview of a Docker Swarm cluster that is based on an SOA. In the next post I will demonstrate a working infrastructure as described above in a Vagrant environment. This post will be coming after our Docker Denver Meetup4 so stay tuned (or better yet, come to the Meetup for the live demo)!
All of the research behind these blog posts was made possible due to the awesome company I work for: Rally Software in Boulder, CO. We get at least 1 hack week per quarter and it enables us to hack on awesome things like Docker Swarm. If you would like to cut to the chase and directly start playing with a Vagrant example, here is the repo that is the output of my Q1 2014 hack week efforts: